 adamkrieger.ca
adamkrieger.caBasic .Net Async for Performance Optimization
Adam Krieger, Wed 25 November 2015, Framework deep dive
Adam Krieger, Wed 25 November 2015, Framework deep dive
Over the next couple of months I'm going to dig into the .Net Threading Library. This is meant to be an intro to System.Threading. Using the .Net ThreadPool incurs overhead, but I wanted to measure how much we'd need to process before that overhead paid off, and when exactly it paid off big. This experiment involves a WebApi project, the .Net 4.5 async/await syntax, and a scalable Azure VM. The code is available on my GitHub account, in the ConcurrencySandbox repository.
It can be tricky to know what performance optimizations will deliver the best bang for the buck. Accurate measurements and benchmarks are required, and the situation is further complicated by the expectations of scale all businesses dream of. A five percent boost may quickly evaporate under an order of magnitude of growth. Optimization is like chess, you must think a few moves ahead in order to truly succeed. My advice is to communicate better with those that know the business. Ask them where you expect to grow, and then make sure that those systems scale first.
Any work done to optimize a process is meaningless without a plan and measurement to prove it.
In a .Net application, there are three layers of abstraction important to note in this context.
System.Threading does give you the ability to create managed threads manually, but the default option is the existing pool. Threads in the pool are pre-initialized, and the pool is capable of growing if a need to do so is detected.
var stopwatch = new Stopwatch();
stopwatch.Start();
computations.DoWork(cycles);
var inOrderSpan = stopwatch.Elapsed;
stopwatch.Restart();
await computations.DoWorkAsync(cycles);
var asyncSpan = stopwatch.Elapsed;
Duration is the concern, so the lightest and simplest way I've found is to use System.Stopwatch(). Call Start() or Restart() before processing, then get Elapsed after you're done. It's a great way to measure the duration at the destination. Also, we're not concerned with how fast the CPU is, since both instructions sets will run on the same unit, but we are very interested to know how many Processors we have access to. We get that number by retrieving Environment.ProcessorCount.
public class Computations
{
public int DoWork(long cycles)
{
var a = Compute(cycles);
var b = Compute(cycles);
return a + b;
}
public async Task<int> DoWorkAsync(long cycles)
{
var a = Task.Run(() => Compute(cycles));
var b = Task.Run(() => Compute(cycles));
return await a + await b;
}
private static int Compute(long cycles)
{
for (var i = 0; i < cycles; i++) { }
return 21; //Half of the answer
}
}
And here's the meat and potatoes. Async methods are marked 'async' after the access identifier, and must return a Task. Basic Tasks are created with a simple lambda, and the stack will return from Run as soon as the Task has been created. Reference to the work done is maintained in the Task. The line await a + await b will actually return a, which is a Task<int>, to the caller. The caller awaits the result immediately though, so we're stuck until both a and b finish up.
Using Task.Run turns control over to the ThreadPool, which negotiates those Tasks into managed threads. The CLR then does its best to work well with the kernel thread scheduler, which is responsible for getting those instructions executed on the physical processor. Despite Resharper's warning about an empty loop, the C# compiler will not optimize it away, and we can use this as a varying instruction set.
So that's a mouthful. We're doing two things concurrently, just two, and both of them look very similar, but the number of moving parts has soared. It had better be worth it, so I recorded the numbers.
| Cycles | Sync (s) | Async (s) | % Efficiency |
|---|---|---|---|
| 1 | 0.0000006 | 0.0002281 | 0.2630425 |
| 10 | 0.0000008 | 0.0002816 | 0.2840910 |
| 100 | 0.0000009 | 0.0002291 | 0.3928416 |
| 1000 | 0.0000041 | 0.0002458 | 1.6680228 |
| 10000 | 0.0000341 | 0.0003602 | 9.4669628 |
| 100000 | 0.0004020 | 0.0005763 | 69.7553358 |
| 1000000 | 0.0034019 | 0.0036157 | 94.0868988 |
| 10000000 | 0.0445249 | 0.0330861 | 134.5728267 |
| 100000000 | 0.3150481 | 0.1715336 | 183.6655326 |
| 1000000000 | 3.2191459 | 1.6207255 | 198.6237583 |
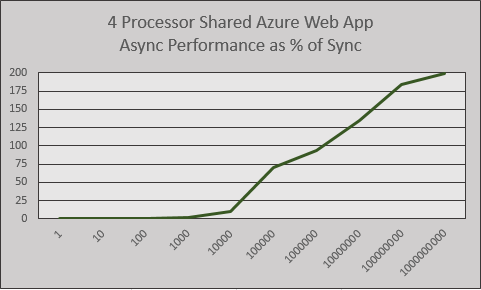
Importantly, the Azure shared Web App instance had 4 processors. While theoretically sharing this VM with many other Apps, this App now has access to more cores than if we'd put it on a single-core paid instance. But more on that later.
At one cycle, the Async performance is an atrocious .28% of the Sync equivalent, and it doesn't get much better until one hundred thousand loops. After that, it steadily climbs up to hit the significant 2:1 factor. At one billion cycles, the same amount of work gets done in half the time. We've proven both Hypothesis 1 and 2 with evidence. Because we've only split the work into two discrete streams, we can be pretty sure that similar results would come out of a two processor VM.
To take a look at Hypothesis 3, all I had to do was hit the 'Scale' tab on the Azure control panel and shift it to a single-core basic instance.
| Cycles | Sync (s) | Async (s) | % Efficiency |
|---|---|---|---|
| 1 | 0.0000007 | 0.0002442 | 0.2866503 |
| 10 | 0.0000007 | 0.0002526 | 0.2771180 |
| 100 | 0.0000010 | 0.0002581 | 0.3874467 |
| 1000 | 0.0000040 | 0.0002420 | 1.6528926 |
| 10000 | 0.0000292 | 0.0002697 | 10.8268446 |
| 100000 | 0.0002869 | 0.0004071 | 70.4740850 |
| 1000000 | 0.0033424 | 0.0036282 | 92.1228157 |
| 10000000 | 0.0359861 | 0.0346644 | 103.8128455 |
| 100000000 | 0.3238972 | 0.3128307 | 103.5375364 |
| 1000000000 | 3.2103357 | 3.2574695 | 98.5530548 |
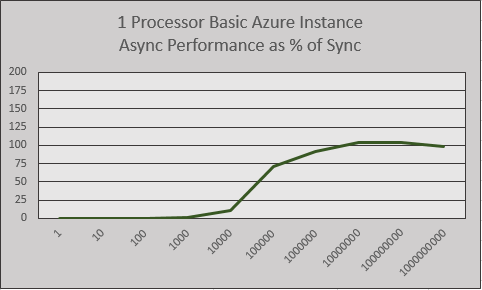
The same curve we saw in the 4 Processor test is present here: from 1 to 100000, the work required starts to outweigh the ThreadPool overhead. After that, we can see how additional cores are valuable, and how concurrent programming is valuable, too. The ThreadPool can't do the same magic when it's physically impossible to execute instructions simultaneously.
We program in an interesting time. Multi-core systems are commonplace, but so are single-core cloud-hosted virtual machines. CPUs are still getting smaller, but they aren't getting much faster without sharply increasing their power input. We have to do more with what we've got, and that means managed-language programmers who are used to moving further away from hardware are now hurtling towards it at an alarming rate. Knowing the lay of the land is key to identifying and realizing performance improvement.
Oh, one more thing. Concurrent programming examples that target performance, but feature Thread.Sleep as the compute substitute, don't hold water.
The 'Clock Tick Rate' determines how much time a thread gets to execute on the processor before the scheduler intervenes and gives the next thread a turn. The default, and therefore most probable, Windows Clock Tick Rate is 15.625ms. When a kernel thread sleeps, it tell the scheduler to give the rest of its Tick to another thread. The scheduler will know when that sleep time is up, and resume queueing the thread afterwards. There's another method, Thread.SpinWait, which does something similar to the experiments above. This method takes a 'cycles' parameter instead of 'milliseconds'.
| Milliseconds | Sync | Async | % Efficiency |
|---|---|---|---|
| 1 | 0.0167834 | 0.0157412 | 106.6208421 |
| 10 | 0.0360317 | 0.0157494 | 228.7814139 |
| 100 | 0.2160496 | 0.1049520 | 205.8556292 |
| 1000 | 2.0150131 | 1.0013177 | 201.2361411 |
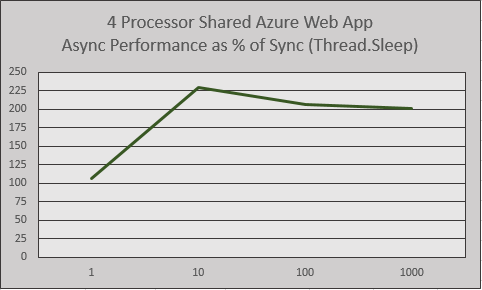
If we went by this example, it would look like anything that took 10ms or longer would see astounding performance boosts by using async/await. Reality carries a lot more nuance. Thanks for reading!
Thanks much,
Adam Krieger